
내가 하고싶은 건 다 하는 공간
혼자 만들면서 공부하는 딥러닝 3-1 MoblieNet 모델, 깊이별 합성곱 | 이미지 분류 모델의 효율성 최적화하기 본문
서론
이전 글에서 DenseNet에 대해 살펴보았는데, 이 모델은 용량이 크다(=파라미터가 많다)는 단점이 있습니다. ResNet보다는 작지만, 이것보다 더 작은 모델인 MobileNet에 대해 알아보고자 합니다.
참고로 모델의 크기에 대해 이야기하자면, 아래와 같습니다.
모델의 크기가 작음 = 파라미터의 개수가 작음 = 실행 속도가 빠름 = 자원 소모 적음
따라서 성능이 비슷하다면 모델의 크기가 작은 것이 좋습니다. 마치 우리가 독서대를 사려는데 비슷하게 생긴 두 제품이 있다면 저렴한 제품을 선택하듯이 말이죠. 깊이별 합성곱을 이용하여 모델의 크기를 줄일 수 있습니다.
깊이별 합성곱 Depthwise Convolution

| 일반 합성곱 | 깊이별 합성곱 | |
| 합성곱 방식 | 모든 채널을 동시에 처리하는 필터 | 채널별 필터로 합성곱 따로 수행 |
| 필터의 깊이 | 입력의 채널 개수 | 1 |
| 필터의 개수 | 직접 지정 | 입력 채널의 개수로 고정 |
| 출력 채널 개수 | 필터의 개수 | 입력 채널의 개수 |
일반 합성곱을 진행할 때에는 1) 필터의 개수와 2) 필터의 크기를 지정해줍니다. 이에 따라 출력 채널 개수가 필터의 개수로 정해집니다. 즉, 일반 합성곱은 출력 채널 개수를 직접 정할 수 있습니다.
반면 깊이별 합성곱은 채널별로 합성곱을 수행하기 때문에 출력 채널의 개수는 입력 채널의 개수와 동일합니다. 이는 채널별로 정보를 분리할 수 있다고 가정한 것입니다. 예를 들어 사진의 이미지가 흑백이 아닌 컬러이고, 3개의 채널이 각각 R, G, B 를 의미할 때, 깊이별 합성곱을 사용한다면 R, G, B의 정보를 분리한다는 의미입니다.
채널별로 정보를 분리하기 때문에 연산 과정이 쉬워지고 따라서 계산의 효율성이 높아집니다.
케라스의 DepthwiseConv2D 클래스
깊이별 합성곱은 DepthwiseConv2D() 클래스로 구현합니다. 일반 합성곱에서는 필터의 개수를 직접 지정해줬지만, 깊이별 합성곱에서는 필터의 개수가 입력 채널의 개수로 고정되어 있으므로 지정할 필요가 없습니다.
깊이별 분리 합성곱 블록 Depthwise Seperable Convolution Block
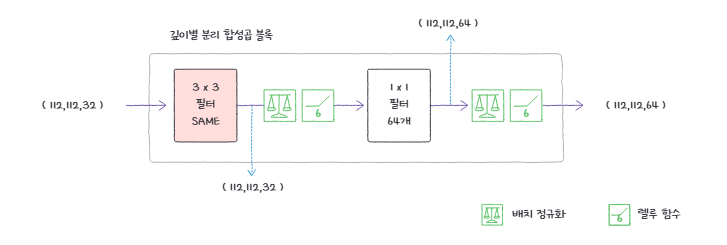
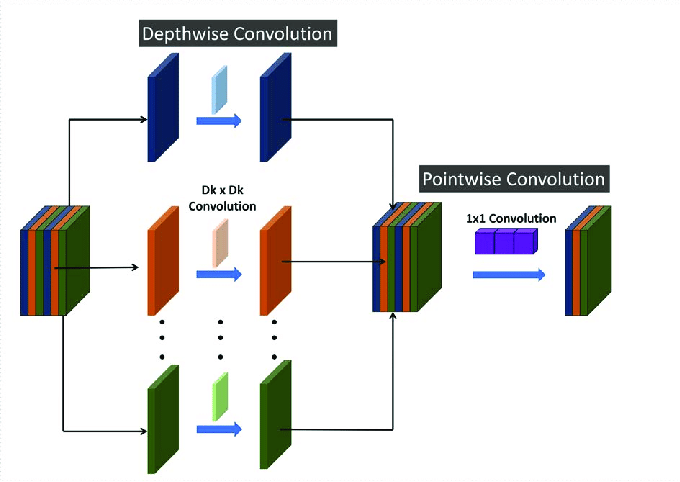
MobileNet 모델은 깊이별 분리 합성곱 블록 Depthwise Seperable Convolution Block을 반복적으로 쌓은 구조입니다. 깊이별 분리 합성곱 블록은 1) 깊이별 합성곱 2) 점별 합성곱 - 이렇게 합성곱을 두 번에 분리해서 진행하는 것이 특징입니다. 하나의 깊이별 분리 합성곱 블록의 구조를 살펴보면 다음과 같습니다:
- 깊이별 합성곱층
- 배치 정규화층
- 렐루 활성화 함수
- 점별 합성곱층: 1 x 1 일반 합성곱 수행, 출력 채널의 개수 지정 가능
- 배치 정규화층
- 렐루 활성화 함수
- 최종 출력 밀집층

여기서 렐루 활성화 함수는 ReLU6를 사용하여 최댓값을 6으로 지정합니다. 이는 활성화 값이 너무 커지는 것을 방지하기 위함입니다. 이를 통해 1) 계산량을 줄이고 2) 그레디언트가 커지는 것을 막으며 3) 모델의 훈련을 안정화할 수 있습니다.
특성 맵의 크기를 줄이는 방법
위에 나온 방법대로 깊이별 분리 합성곱 블록을 만들면 특성 맵의 크기가 계속 줄어들지 않고, 차원의 개수만 지정 가능합니다. 특성 맵의 크기가 줄어들지 않으면 신경망의 깊이가 깊어질수록 더 복잡한 연산을 수행하느라 리소스가 크다는 단점이 있습니다.
따라서 특성 맵의 크기를 줄이기 위해서 합성곱층에서 strides = 2로 겅중겅중 건너가줍니다. 또한 패딩을 사용하지 않고 깊이별 분리 합성곱 블록을 만듭니다.
깊이별 분리 합성곱 블록 구현하기
def depthwise_separable_block(inputs, filters, strides=1):
if strides == 1:
x = inputs
else:
x = layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(inputs) # 위 0, 아래 1, 왼쪽 0, 오른쪽 1픽셀 추가
# 1. 깊이별 합성곱층
x = layers.DepthwiseConv2D(3, padding='same' if strides == 1 else 'valid',
strides=strides, use_bias=False)(x)
x = layers.BatchNormalization(epsilon=1e-5)(x)
x = layers.ReLU(max_value=6.0)(x)
# 2. 점곱 합성곱층
x = layers.Conv2D(filters, 1, padding='same', use_bias=False)(x)
x = layers.BatchNormalization(epsilon=1e-5)(x)
x = layers.ReLU(max_value=6.0)(x)
return x
마무리
이렇게 깊이별 합성곱, 깊이별 분리 합성곱 블록에 대해 알아보았고, 다음 글에서는 이를 활용한 MobileNet에 대해 정리해보겠습니다:)
'인공지능' 카테고리의 다른 글
| 혼자 만들면서 공부하는 딥러닝 3-2 EfficientNet | 고급 CNN 모델과 전이 학습으로 이미지 분류하기 (0) | 2025.07.27 |
|---|---|
| 혼자 만들면서 공부하는 딥러닝 3-1 MoblieNet 모델 구현 | 이미지 분류 모델의 효율성 최적화하기 (2) | 2025.07.27 |
| 혼자 만들면서 공부하는 딥러닝 3-1 DenseNet 모델 구현 | 이미지 분류 모델의 효율성 최적화하기 (0) | 2025.07.27 |
| 혼자 만들면서 공부하는 딥러닝 3-1 DenseNet 모델 준비 | 이미지 분류 모델의 효율성 최적화하기 (1) | 2025.07.27 |
| 혼자 만들면서 공부하는 딥러닝 2-3 GoogLeNet : 인셉션 모듈 Inception Module (0) | 2025.07.20 |



