
우당탕탕 개발일지
[혼공머신] 3-2 K-최근접 이웃의 한계, 선형 회귀, 모델 파라미터, 다항 회귀 본문
💡 K-최근접 이웃의 한계
K-최근접 이웃 모델은 근처에 있는 샘플값의 평균으로 예측하는 모델인데,
새로운 샘플이 훈련 세트의 범위를 벗어나면 엉뚱한 값을 예측할 수 있다는 한계점이 있다.
예를 들어 길이가 50cm인 농어의 무게를 예측했을 때,
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors = 3)
# K-최근접 이웃 회귀 모델 훈련
knr.fit(train_input, train_target)
# 위 모델을 이용하여 길이기 50cm인 농어의 무게 예측
print(knr.predict([[50]]))예측값이 1033.333으로 실제값과 매우 차이가 났다.
import matplotlib.pyplot as plt
# 50cm 농어의 이웃 구하기
distances, indexes = knr.kneighbors([[50]])
# 훈련 세트를 산점도로 나타내기
plt.scatter(train_input, train_target)
# 훈련 세트 중에 이웃 샘플 3개만 다이아몬드로 표시하기
plt.scatter(train_input[indexes], train_target[indexes], marker = "D")
# 모델이 예측한 50cm 농어 의 무게를 삼각형으로 표시하기
plt.scatter(50, 1333, marker = "^")
# 마무리
plt.xlabel("length")
plt.ylabel("weight")
plt.show()
문제의 원인을 파악하기 위해 산점도 위에 예측에 활용한 샘플값 3개, 새로운 샘플을 표시해보았다.

예측하고자 하는 새로운 샘플값(삼각형)이 훈련 세트들과 동떨어져있음을 알 수 있다.
이런 경우라면 새로운 샘플값이 50 이상이더라도 예측에 활용하는 세 개의 샘플값은 동일하기 때문에 똑같이 1033.333으로 무게를 예측하게 되는 문제가 발생한다.
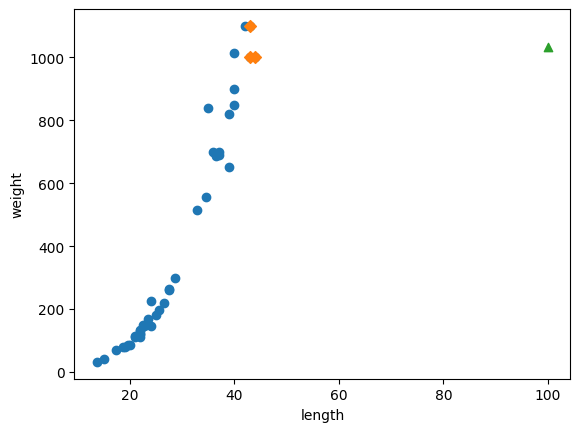
실제로 길이가 100인 새로운 샘플값을 넣어서 확인해보면 다음과 같다.
이러한 문제를 해결하는 알고리즘이 선형 회귀이다.
💡 선형 회귀
선형 회귀는 널리 사용되는 대표적인 회귀 알고리즘으로, 전체 데이터의 경향을 직선으로 나타낸다.
사이킷런의 LinearRegression 클래스로 선형 회귀와 다중 회귀 모두 진행한다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 선형 모델 훈련
lr.fit(train_input, train_target)
# 50cm 농어에 대해 예측
print(lr.predict([[50]]))k-최근접 이웃 회귀를 사용했을 때에는 1033으로 예측했는데,
선형 회귀를 사용하니 값이 1242로 더 값이 크게 나왔다.
왜 이런 값을 예측했는지 알아보기 위해 모델 파라미터를 알아보자!
💡모델 파라미터
: 머신 러닝 모델이 데이터를 기반으로 학습하면서 조정하는 내부 변수

선형 회귀 모델에서는 내부 변수 = 기울기와 y절편이다.
머신러닝에서 기울기를 종종 계수(coefficient) 또는 가중치(weight)라고 부르기도 한다.
즉, 선형 회귀 모델은 훈련 데이터를 기반으로한 학습을 통해 최적의 모델 파라미터를 찾는다.
이를 모델 기반 학습이라고 부른다.
참고로, 기타 머신 러닝 모델에서도 파라미터가 있다.
- 로지스틱 회귀: 로지스틱 회귀에서도 파라미터는 회귀 계수이다.
- 신경망: 각 층의 가중치(weight)와 편향(bias)이 파라미터이다.
- 서포트 벡터 머신 (SVM): 서포트 벡터와 경계면을 정의하는 가중치와 편향이 파라미터이다.
- 결정 트리: 각 노드에서의 분할 기준이 파라미터이다.
💡회귀 직선 시각화
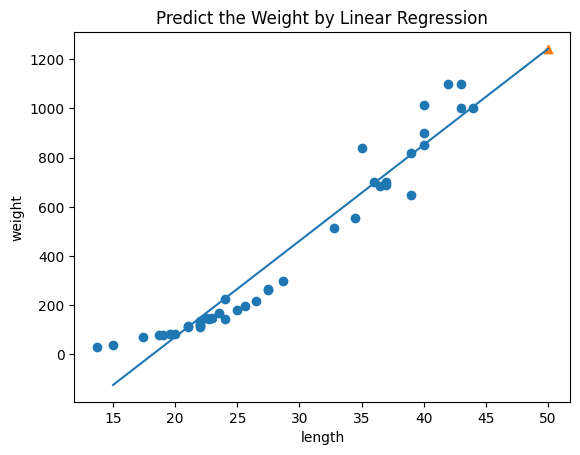
산점도 위에 회귀 직선을 나타내면 다음과 같다.

💡다항 회귀
: 선형 회귀의 확장으로, 독립 변수와 종속 변수 간의 비선형 관계를 모델링하는 방법이다.
다항 회귀는 종속 변수와 독립 변수 사이의 관계를 다항식 형태로 표현한다.
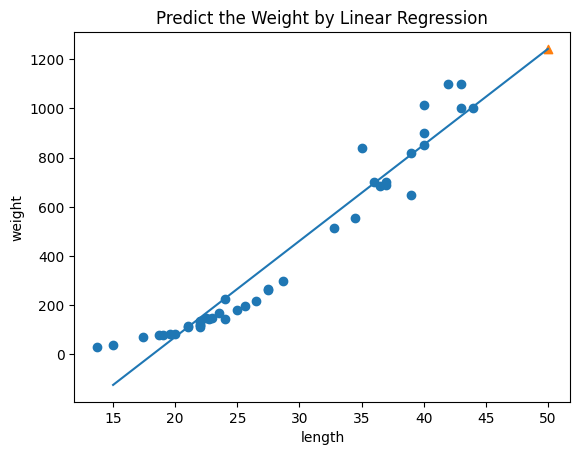
이 산점도를 보면 직선이 아니라 곡선의 형태를 띄고 있다.
따라서 1차가 아닌 2차 방정식의 그래프를 그리고자 한다.
무게 = a * 길이^2 + b * 길이 + c
# 2차 방정식을 도출하기 위해 길이 특성을 제곱한 새로운 특성을 만든다.
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_stack((test_input**2, test_input))
print(train_poly.shape, test_poly.shape)
다항 회귀 모델을 훈련한 결과 모델 파라미터를 계산할 수 있다.
무게 = 1.014 * 길이^2 - 21.558 * 길이 + 116.050
💡다항 회귀 곡선 시각화
무게 = 1.014 * 길이^2 - 21.558 * 길이 + 116.050
이 다항 회귀 방정식을 산점도 위에 나타내면 다음과 같다.
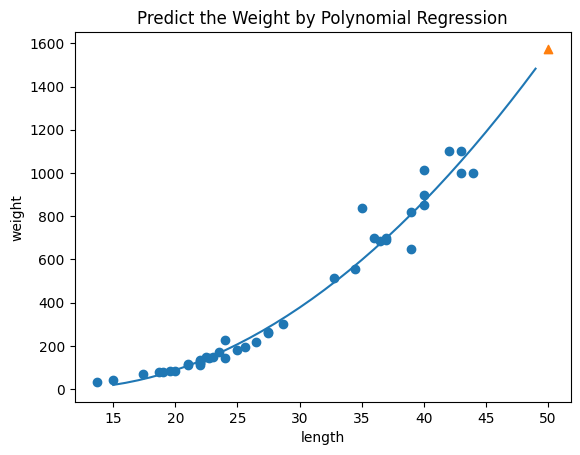

단순 선형 회귀와 비교하였을 때 훈련 세트와 테스트 모두 점수가 크게 높아졌다!
'인공지능' 카테고리의 다른 글
| [데이터 분석 경진대회] 대기오염 데이터 분석을 통한 예측모델 개발 및 대기질 지수 산정예측 (1) | 2024.09.28 |
|---|---|
| [혼공머신] 4-1. 로지스틱 회귀 (0) | 2024.07.21 |
| [혼공머신] 3-3 다중 회귀, 특성 공학, 사이킷런의 변환기 클래스 PolynomialFeatures (0) | 2024.07.14 |
| [혼공머신] 3-1 과대적합과 과소적합의 차이, 과소적합 해결 방법, 확인문제 (0) | 2024.07.13 |
| [혼공머신] 3-1 K-최근접 이웃 회귀, 회귀분석, 결정계수(R^2), 데이터 준비 (1) | 2024.07.13 |



