과소적합(Underfitting): 훈련 세트의 점수 < 테스트 세트의 점수
과대적합 = 훈련 세트에서만 잘 맞는 모델 = 실제 상황에서는 예측 정확도가 떨어짐
과소적합 = 모델이 너무 단순해서 or 훈련 세트의 크기가 너무 작아서 훈련 제대로 못함
과소적합을 해결하는 방법
: k-최근접 이웃 회귀 모델에서 이웃의 개수 k를 줄여서 모델을 더 복잡하게 만든다.
이웃의 개수를 줄이면 훈련 세트에 있는 국지적인 패턴에 민감해져서 모델이 복잡해진다.
사이킷런의 k-최근접 이웃 알고리즘의 기본 k값은 5이기 때문에, 아래의 코드를 통해 바꿔주면 된다.
knr.n_neighbors = 3
결과를 보면 훈련 세트의 점수가 높아지고, 테스트 세트의 점수가 낮아졌다.
즉, 과소적합을 해소했다고 볼 수 있다.
확인문제
# k-최근접 이웃 회귀 객체 만들기
knr = KNeighborsRegressor()
# 5에서 45까지의 x 좌표 만들기
x = np.arange(5, 45).reshape(-1, 1)
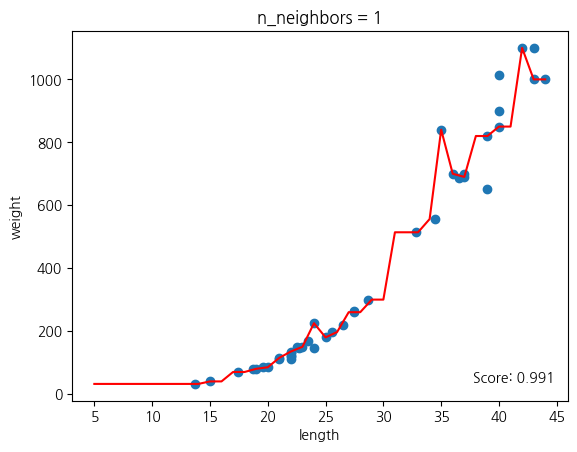
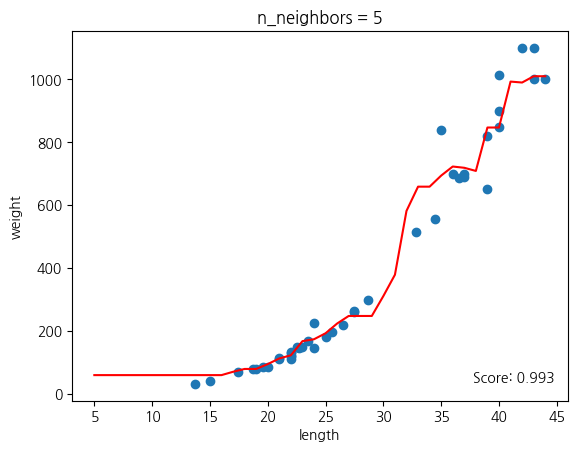
# n = 1, 5, 10일 때 예측 결과를 그래프로 나타내기
for n in [1, 5, 10]:
# 모델을 훈련하기
knr.n_neighbors = n
knr.fit(train_input, train_target)
# 지정한 범위 x에 대한 예측을 구하기
prediction = knr.predict(x)
# 훈련 세트와 예측 결과를 그래프로 나타내기
plt.scatter(train_input, train_target)
plt.plot(x, prediction, color = "red")
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
과대적합과 과소적합에 대한 이해를 돕기 위해 k-최근접 이웃 회귀 모델의 k값을 각각 1, 5, 10으로 바꿔가며 훈련한다.
n의 값이 커질수록 선이 단순해지고, n의 값이 작을수록 촘촘한 그래프가 그려진다.
n이 작으면 오버슈팅(과대적합), n이 크면 언더슈팅(과소적합)이 발생함을 확인할 수 있다.