
우당탕탕 개발일지
[DFS] 이것이 코딩테스트다 본문
DFS/BFS... 생전 처음 들어보는 내용이라 더욱더 자세하게 정독했다.
일단 DFS/BFS를 시작하기 전에 탐색, 자료구조, 오버플로, 언더플로, 스택, 큐, 재귀함수 등의 용어를 알아야 한다.
탐색 = 원하는 데이터를 찾는 과정
자료구조 = 데이터를 표현하고 관리하고 처리하기 위한 구조(스택과 큐가 자료구조의 개념)
- 삽입(Push) & 삭제(Pop)
스택 vs 큐
- 스택은 선입후출, 큐는 선입선출
큐
- 큐를 구현할 때 collections 모듈에서 제공하는 deque 자료구조 활용
- from collections import deque
queue = deque()
queue.popleft() #왼쪽에 삭제
queue.append() #오른쪽에 삽입
queue.reverse() #리스트 자체의 원소 순서를 거꾸로 바꿔준다(queue[::-1]은 출력할 때만 순서를 거꾸로 할 뿐, 실제 queue의 원소 순서는 기존과 동일
재귀함수 = 자기 자신을 다시 호출하는 함수
DFS = Depth First Search 깊이 우선 탐색

이렇게 생긴 노드-간선의 관계를 두 가지 방식으로 나타낼 수 있다.
예시로 각 노드가 0, 1, 2이고, 간선이 7, 5인 아래의 케이스를 이용한다.

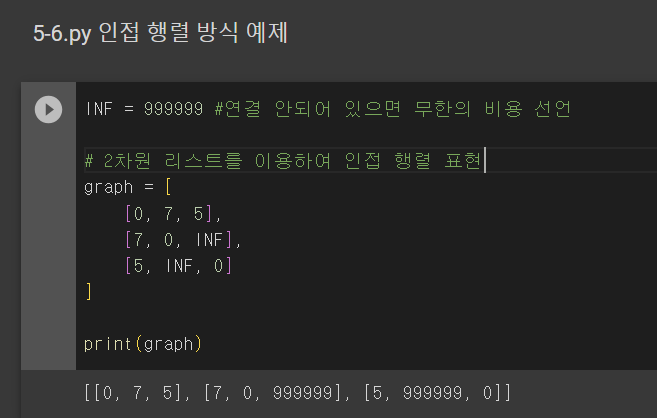
1. 인접 행렬 방식: 2차원 배열로 연결 관계 표현
모든 관계를 저장하므로 노드 개수가 많을수록 메모리가 불필요하게 낭비된다.
2. 인접 리스트 방식: 연결 리스트로 연결 관계 표현
연결된 정보만을 사용하기 때문에 메모리를 효율적으로 사용할 수 있다.

그래서! 아무튼 DFS의 동작 플로우는 다음과 같다.
1. 탐색 시작, 탐색한 노드를 스택에 삽입하고 방문처리한다
2. 하나의 노드를 탐색한 후에는 주변 노드 중 가장 작은 수 먼저 탐색한다(방문처리 잊지말기)
3. 더 이상 탐색할 노드가 없으면 이전 노드로 되돌아가고, 스택에서 최상단 노드를 꺼낸다(후입선출)
4. 2, 3을 반복한다.
예제 소스코드
# DFS 메서드 정의
def dfs(graph, v, visited):
# 탐색한 노드를 방문 처리
visited[v] = True
print(v, end = ' ')
# 인접한 노드를 재귀적으로 방문
for i in graph[v]:
# 방문한 적이 없는 노드일 경우
if not visited[v]:
dfs(graph, i, visited)
graph = [
[],
[2,3,8],
[1,7],
[3,5],
[3,4],
[7],
[2,6,8],
[1,7]
]
visited = [False]*9
dfs(graph, 1, visited)'알고리즘' 카테고리의 다른 글
| [알고리즘 문제 꿀팁] 입력값 간단하게 받는 방법 (1) | 2023.11.01 |
|---|---|
| [BFS] 이것이 코딩테스트다 (1) | 2023.10.30 |
| [알고리즘] 백준 2828번 사과 담기 문제 (0) | 2023.10.02 |
| [기초-3항연산] 정수 2개 입력받아 큰 값 출력하기 (0) | 2023.09.28 |
| [기초-비트단위논리연산] 비트단위로 출력하기 (0) | 2023.09.27 |
