
내가 하고싶은 건 다 하는 공간
혼자 만들면서 공부하는 딥러닝 2-2 강아지와 고양이 사진 분류하기 본문
서론
2-2장의 제목은 사전 훈련된 CNN 모델로 강아지와 고양이 사진 분류하기입니다. 이것을 수행하기 위해서는 당연히 1) 사전 훈련된 CNN 모델과 2) 강아지와 고양이 사진이 필요하겠죠.
사전 훈련된 CNN 모델 불러오기
# VGG16() 함수 호출하기
import keras
vggnet = keras.applications.VGG16()케라스에는 VGGNet을 포함하여 다양한 모델이 내장되어 있습니다. 모델의 가중치까지 포함되어 있기 때문에 편리하게 모델을 가져다가 사용할 수 있다는 장점이 있습니다. 혹시 초기화된 가중치를 사용하고 싶다면 weights = None 파라미터를 추가하면 됩니다.
강아지와 고양이 사진 가져오기
# 이 책의 깃허브 저장소에 있는 강아지와 고양이 샘플 이미지 가져오기
!gdown 1xGkTT3uwYt4myj6eJJeYtdEFgTi2Sj8C
!unzip cat-dog-images.zip
책에서는 한 장의 강아지 사진과 한 장의 고양이 사진이 주어집니다.
구글 코랩 환경에서 좌측 폴더 아이콘을 클릭하여 images 폴더 안에 총 2장의 이미지가 있음을 파악하였습니다.

크기는 가로 224 세로 224이네요. 컬러 이미지이기 때문에 깊이는 3이 되었습니다. 참고로 딥러닝 모델들은 이미지 데이터를 처리할 때 수치형 배열 Numerical Array 형태로 받기 때문에 사진 데이터를 np.array로 바꿔줍니다.
강아지와 고양이 사진 분류하기
이미지 전처리 Image Preprocessing: 사전 훈련된 합성곱 신경망을 사용해서 예측하기 전에 수행해야 하는 작업
이 작업을 사전에 거쳐야합니다. 다행히도 케라스에서 각 모델의 이미지 전처리 방법도 제공하고 있습니다.
from keras.applications import vgg16
vgg_prep_dog = vgg16.preprocess_input(dog_array)dog_array를 이미지 전처리해서 vgg_prep_dog로 만들어줍니다.

그 다음에는 vgg_prep_dog을 vggnet.predict 메서드 안에 넣어서 예측 결과를 predictions에 담습니다. predictions의 크기는 1 x 1000입니다. 이는 1000개의 클래스(동물의 종류)에 대한 확률값을 나타내고 있습니다.

결과를 보니 208클래스로 분류될 확률이 35.7%로 매우 높네요.
모델 출력 디코딩하기
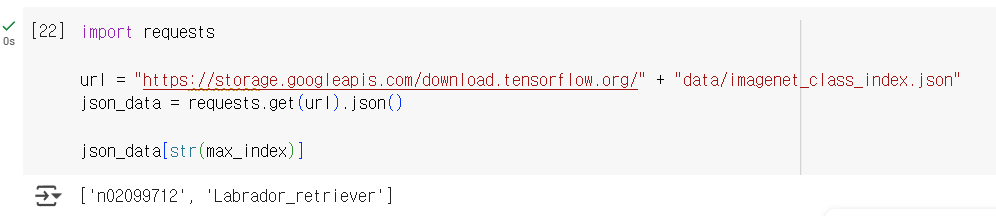
구글 클라우드 스토리지 Google Cloud Storage에 저장된 이미지넷 클래스 파일의 경로를 url 변수에 담고, requests.get 메서드를 이용하여 JSON 객체로 디코딩하여 확인했습니다. 그 결과 강아지의 품종이 Labrador Retriever임을 확인할 수 있습니다. 참고로 n02099712는 이미지넷 클래스에 대한 고유 ID값을 의미합니다.
이렇게 JSON 객체로 디코딩해서 확인할 수 있지만 번거롭기 때문에, 보통은 decode_predictions 함수를 사용합니다.
확률이 가장 높은 클래스 디코딩

decode_predictions 함수를 사용하여 가장 확률이 높은 클래스를 확인할 수 있고, top 파라미터의 숫자를 변경하여 상위 몇 개의 클래스를 반환할 것인지 결정할 수 있습니다. 결국 이 사진 속 강아지는 Labrador_retriever로 분류되네요!
책에 없는 내용: 확률이 높은 상위 10개의 클래스 디코딩
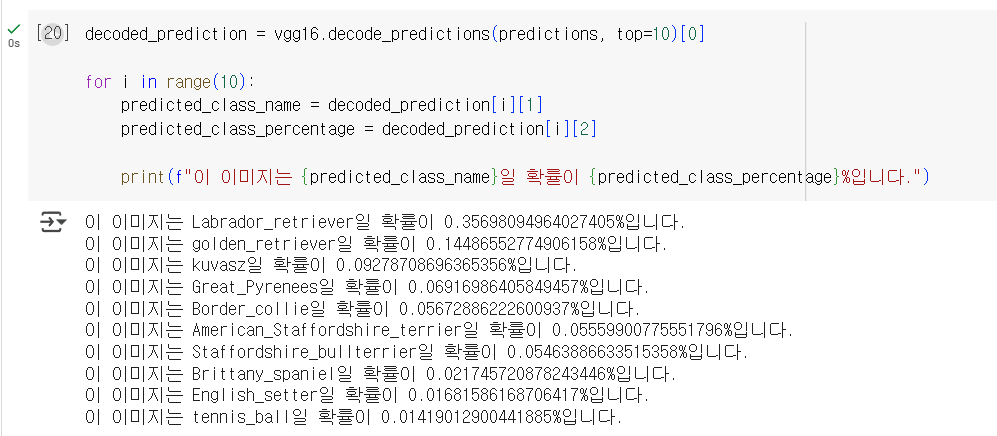
일단 위 코드를 통해 top1부터 top10까지 나열해보았고, 아래에는 seaborn을 사용하여 각 클래스로 분류될 확률을 시각화해보았습니다.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from keras.applications import vgg16
# Get the top 10 predicted class indices and their probabilities
top_10_indices = np.argsort(predictions.flatten())[-10:][::-1]
top_10_probabilities = predictions.flatten()[top_10_indices]
# Get the class labels
# VGG16 comes with a utility function to decode predictions into human-readable labels
decoded_predictions = vgg16.decode_predictions(predictions.copy(), top=10)[0]
# Prepare labels for the plot (class name and probability)
labels = [f"{label[1]} ({label[2]:.2f})" for label in decoded_predictions]
# Create a horizontal bar chart using seaborn with rainbow color map
plt.figure(figsize=(12, 6))
# Use the probabilities to influence the color intensity
colors = sns.color_palette('rainbow', n_colors=len(top_10_probabilities))
# Sort colors based on probability (descending)
sorted_colors = [colors[i] for i in np.argsort(top_10_probabilities)][::-1]
sns.barplot(x=top_10_probabilities, y=labels, palette=sorted_colors)
plt.xlabel("Probability")
plt.ylabel("Predicted Class")
plt.title("Top 10 Predicted Classes (Seaborn Rainbow)")
plt.tight_layout()
plt.show()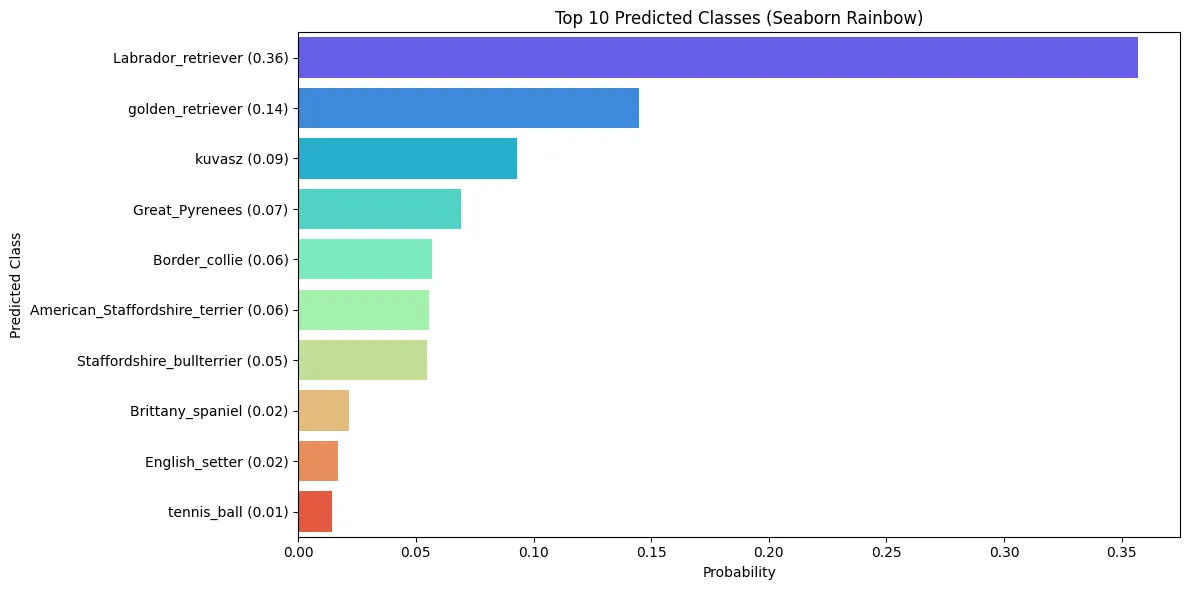
여기서도 마찬가지로 dog_png 사진을 보고 Labrador_retriever로 예측할 확률이 가장 큼을 확인할 수 있습니다.
고양이 사진 분류하기
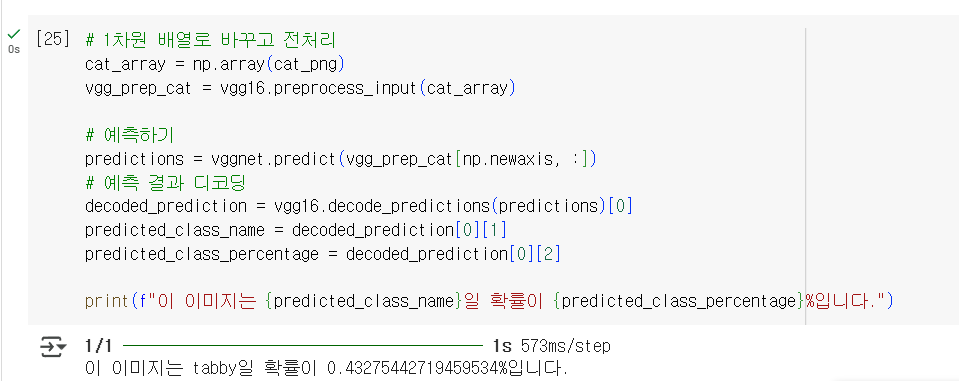
고양이도 강아지와 마찬가지로 진행해주면 됩니다.
'인공지능' 카테고리의 다른 글
| 혼자 만들면서 공부하는 딥러닝 2-3 GoogLeNet : 인셉션 모듈 Inception Module (0) | 2025.07.20 |
|---|---|
| 혼자 만들면서 공부하는 딥러닝 2-3 ResNet : 분류 모델 성능 개선하는 CNN 모델 (0) | 2025.07.20 |
| 혼자 만들면서 공부하는 딥러닝 2-1 이미지 분류 CNN 모델: VGGNet 모델 구조 분석하기 (0) | 2025.07.20 |
| 혼자 만들면서 공부하는 딥러닝 2-1 이미지 분류 CNN 모델: AlexNet 모델 구조 분석하기 (0) | 2025.07.20 |
| 혼자 만들면서 공부하는 딥러닝 1-3 패션 상품 이미지 분류하기: 잘못 분류된 데이터 살펴보기 (2) | 2025.07.13 |

