

우당탕탕 개발일지
[혼공머신] 6-3. 주성분 분석 본문
💡 서론
지금까지 6장에서 사용한 데이터는 100*100개의 픽셀로 이루어진 이미지 데이터, 즉 10000개의 특성을 가진 데이터였다. 만개는 너무 많기 때문에, 이 중에서 각 이미지를 가장 잘 나타내는 일부 특성을 선택해서 데이터 크기도 줄이고 성능도 향상시키고자 한다.
💡 차원 축소(Dimensionality Reduction)
위에서 언급한 방법이 바로 차원 축소(Dimensionality Reduction)이다. 머신러닝에서는 차원 = 특성이라고 봐도 된다.
특성의 개수를 줄여서, 즉 차원 축소를 통해 데이터의 크기를 줄이고 모델의 성능도 향상시킨다.
💡 주성분 분석(Principal Component Analysis)
그러면 어떤 특성을 선택하면 좋을까? 물론 데이터를 가장 잘 나타내는 특성을 선택해야겠지만, 어떤 특성이 데이터를 가장 잘 나타내는지 파악하려면 대표적인 차원 축소 알고리즘인 주성분 분석(Principal Component Analysis)를 사용하면 된다.
이건 최근에 전공수업 들은 부분이라 필기내용을 가져왔다.



💡 PCA 클래스
주성분 분석은 사이킷런의 sklearn.decomposition 모듈 아래 PCA 클래스로 진행한다.

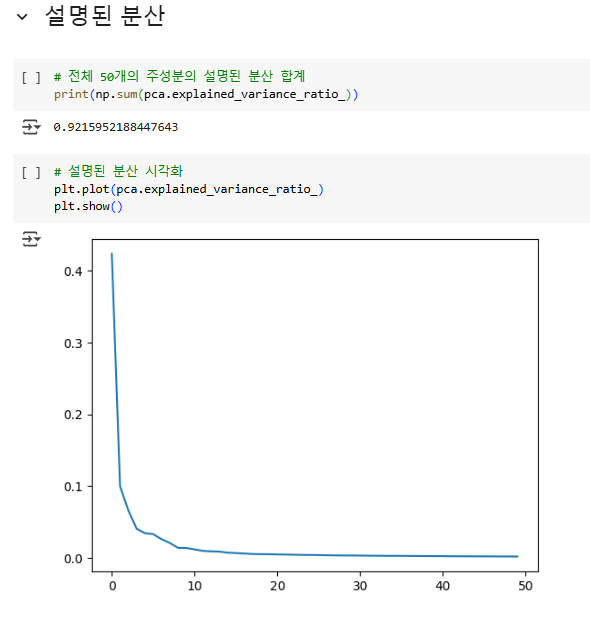
처음 10개의 주성분이 대부분의 분산을 표현하고 있음을 알 수 있다. 주성분 분석은 로지스틱 회귀, k-평균 알고리즘 등 다른 알고리즘과 함께 사용될 수 있다.
💡 확인 문제

1. 특성의 개수만큼 주성분을 찾을 수 있다. 다만 '특성의 개수 = 주성분의 개수'라면 차원축소하는 의미가 없기 때문에 보통 80% 정도로 정한다.
2. 원래 특성의 개수가 100인데, 주성분 분석을 통해 10개의 주성분을 찾은 상황이다. 그러니 데이터셋의 크기가 (1000, 100) 에서(1000, 100)으로 줄어든다.
3. 항상 첫 번째 주성분이 가장 설명력이 높다.
'인공지능' 카테고리의 다른 글
| [혼공머신] 7-2. 심층 신경망 (0) | 2025.02.23 |
|---|---|
| [혼공머신] 7-1. 인공 신경망 (0) | 2025.02.23 |
| [혼공머신] 6-2. K-평균 (1) | 2025.02.04 |
| [혼공머신] 6-1. 군집 알고리즘 (0) | 2025.02.04 |
| [혼공머신] 5-3. 트리의 앙상블 (0) | 2025.01.28 |


