
우당탕탕 개발일지
[혼공머신] 5-2. 교차 검증과 그리드 서치 본문

💡 서론
교차 검증(Cross Validation)과 그리드 서치(Grid Search) 모두 결론적으로 예측 모델의 성능을 향상시키기 위함이다.
5-2장에서는 검증 세트, 교차 검증, 그리드 서치, 랜덤 서치 등 다양한 개념이 나오는데
결론적으로 보면 다 좋은 모델을 만들기 위함이다.
💡 목차
1. 검증 세트
2. 교차 검증(Cross Validation)
3. 하이퍼파라미터 튜닝(Hyperparameter Tuning)
💡 검증 세트
검증 세트 이전에는 전체 데이터를 단순히 training set과 test set으로 나누었다.
이렇게 테스트 세트를 사용해 자꾸 성능을 확인하다 보면 점점 테스트 세트에 맞추게 된다. 즉, 일반화가 되지 않고 테스트 세트에만 잘 맞는 모델을 개발하게 되는 문제점이 발생한다.
이러한 문제점을 해결하고자 훈련 세트를 다시 훈련 세트와 검증 세트로 나눈다.
각 데이터 세트는 아래의 역할을 수행한다.
1. Train Set: 모델을 훈련(sub_input, sub_target)
2. Validation Set: 모델을 평가하여 과대적합인지 과소적합인지 판단(val_input, val_target)
3. Test Set: 마지막에 테스트 세트에서 최종 점수를 평가(test_input, test_target)
실제로 코랩환경에서 훈련 세트와 검증 세트, 테스트 세트를 나누어보았다.
검증 세트가 추가되는 경우 훈련 세트는 train_input 대신 sub_input으로 명시해준다. 헷갈리지 않게 이 규칙을 계속 지키면 좋을 것 같다.
💡 교차 검증(Cross Validation)
이전에는 단순히 테스트 세트만으로 모델의 성능을 평가했다.
그러나 이제는 검증 세트를 이용해서 모델의 성능을 평가하는데, 검증세트를 너무 조금 떼어 놓으면 검증 점수가 들쭉날쭉하다는 문제가 발생한다.
이 문제를 해결하고자 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복하는 교차 검증(Cross Validation) 개념이 도입되었다.
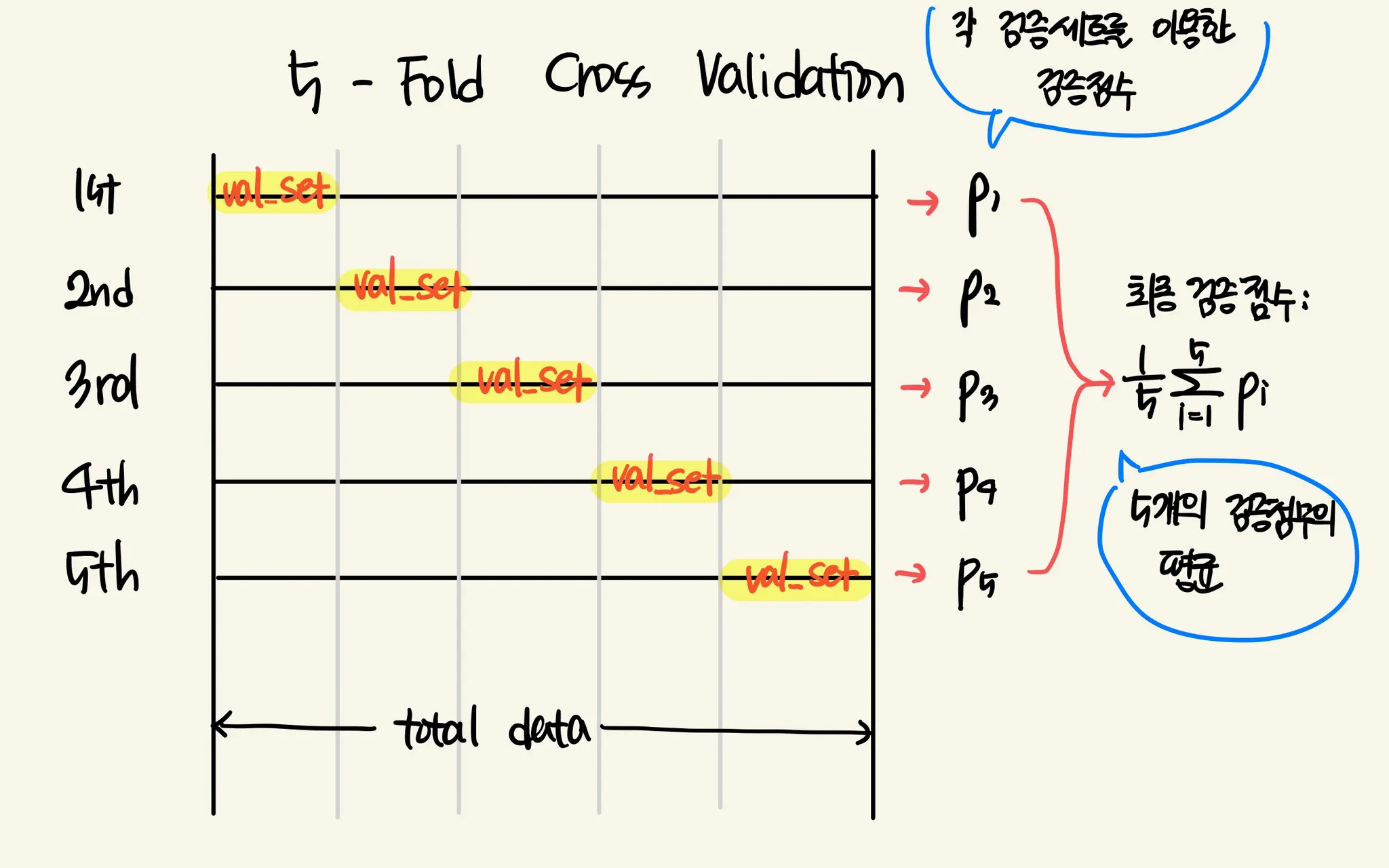
훈련 세트를 k개의 부분으로 나눠서 교차 검증을 수행하는 것을 K-폴드 교차 검증이라고 한다.
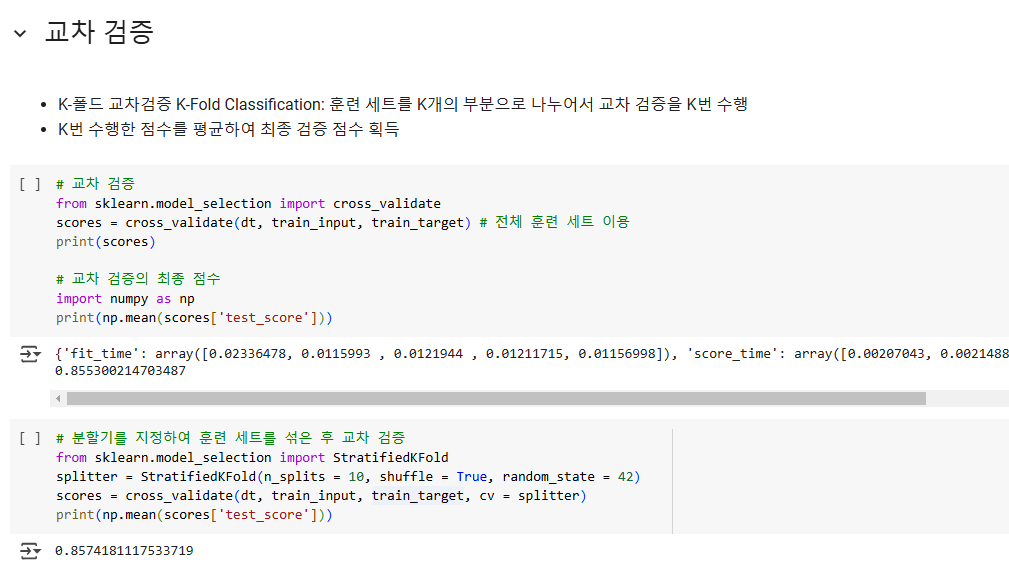
사이킷런에는 cross_validation()라는 교차 검증 함수를 이용할 수 있다. 이는 기본적으로 5-폴드 교차 검증을 수행하고, cv 매개변수를 이용해서 폴드 수를 바꿀 수 있다.
분할기(Splitter)를 지정하면 교차 검증을 할 때 훈련 세트를 섞은 후에 진행한다. StratifiedKFold를 통해 타깃 클래스를 골고루 나눠준다.
💡 하이퍼파라미터 튜닝(Hyperparameter Tuning)
하이퍼파라미터: 머신러닝 모델이 학습할 수 없어서 사용자가 지정해야하는 파라미터
하이퍼파라미터 튜닝: 하이퍼파라미터를 바꿔가면서 가장 성능이 좋은 파라미터 조합을 찾는 과정
여기서 주의할 점은, 매개변수(파라미터)는 서로 영향을 미친다는 점이다.
따라서 하이퍼파라미터의 모든 조합을 탐색하며 최적의 성능을 보이는 하이퍼파라미터 조합을 찾아야 한다.
그리드 서치(Grid Search)

사이킷런에서 제공하는 GridSearchCV 클래스를 이용하면 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행할 수 있다.
<그리드 서치를 사용하는 방법>
1. params = {}에 탐색할 파라미터를 명시한다.
2. gs = GridSearchCV() 객체를 생성한다.
3. gs 객체 안에 1) 탐색 대상 모델, 2) 탐색할 매개변수, 3) n_jobs 매개변수를 넣는다.
gs = GridSearchCV(DecisionTreeClassifier(random_state = 42), params, n_jobs = -1)4. 훈련이 끝나면 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델을 훈련한다.
gs.fit(train_input, traini_target)5. 이 최적의 모델은 gs 객체의 best_estimator_속성에 저장되어 있다.
dt = gs.best_estimator_
print(dt.score(train_input, train_target))6. 이 최적의 모델의 매개변수는 best_params_ 속성에 저장되어 있다.
print(gs.best_params_)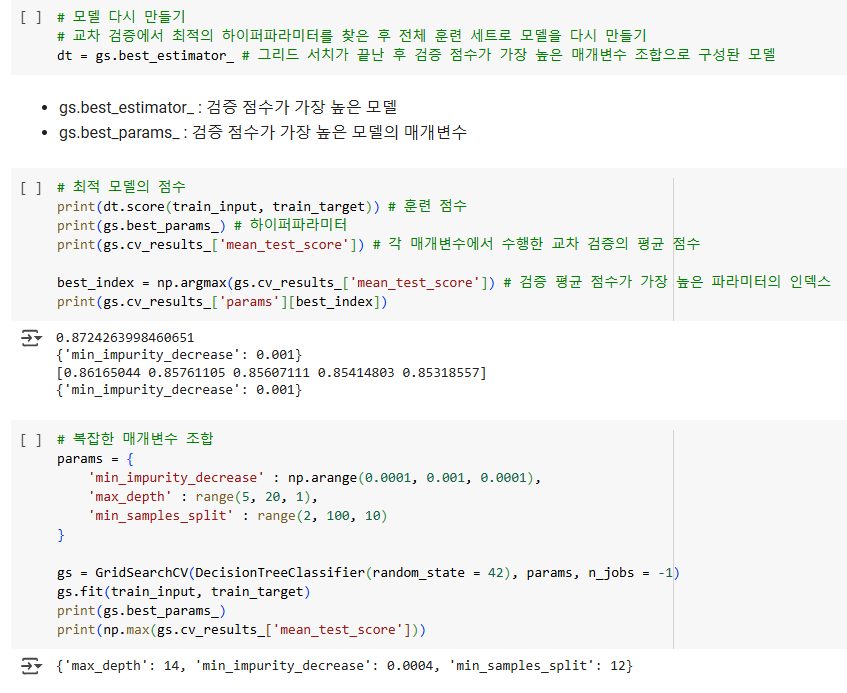
랜덤 서치(Random Search)
랜덤 서치는 그리드 서치와 동일하게 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행한다.
그러나 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달한다.
확률 분포 객체
from scipy.stats import uniform, randint- uniform: 범위 내에 있는 실숫값을 랜덤하게 뽑는다.
- randint: 범위 내에 있는 정숫값을 랜덤하게 뽑는다.
확률 분포 객체를 이용하여 탐색할 매개변수를 랜덤하게 뽑는다.
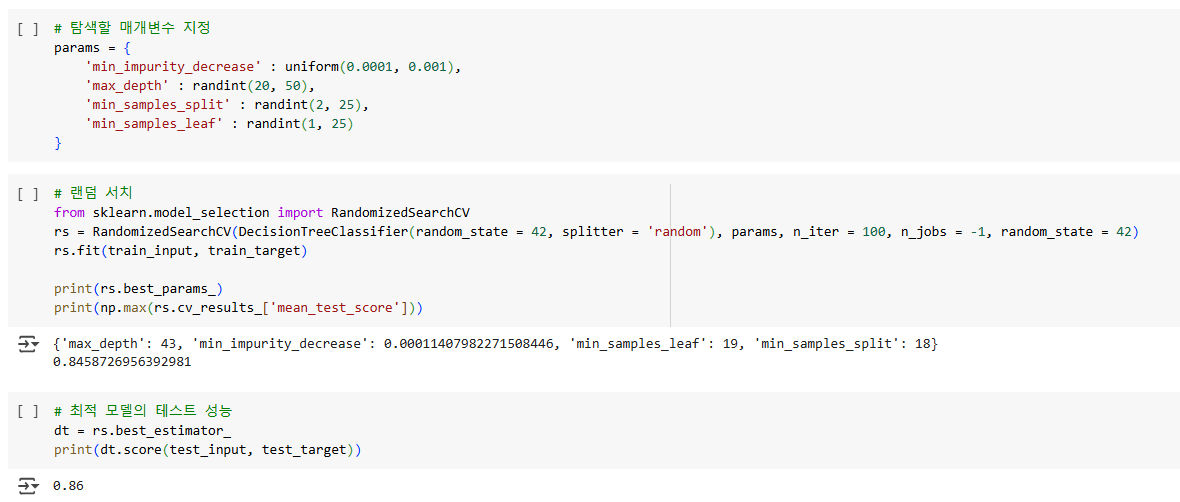
랜덤 서치를 이용하면 그리드 서치보다 교차 검증 수를 줄이면서 넓은 영역을 효과적으로 탐색할 수 있다.
'인공지능' 카테고리의 다른 글
| [혼공머신] 6-1. 군집 알고리즘 (0) | 2025.02.04 |
|---|---|
| [혼공머신] 5-3. 트리의 앙상블 (0) | 2025.01.28 |
| [혼공머신] 5-1. 결정트리 (0) | 2025.01.24 |
| [혼공머신] 4-2. 확률적 경사 하강법 (1) | 2025.01.14 |
| [혼공머신] 4-1. 로지스틱 회귀 (0) | 2025.01.14 |



