
내가 하고싶은 건 다 하는 공간
[혼공머신] 2-2 데이터 전처리 본문
💡 데이터 전처리에 활용되는 넘파이 함수
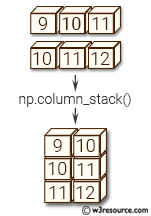
column_stack() 함수
전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결
각 특성값을 담은 두 리스트를 합쳐서 입력 데이터를 만드는 데에 활용
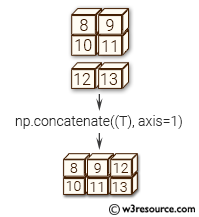
concatenate() 함수
전달받은 리스트를 옆으로 붙인다. axis = 1으로 하면 열을 기준으로 붙인다.
타깃 데이터를 만드는 데에 활용
💡사이킷런으로 훈련 세트와 테스트 세트 나누기
train_test_split() 함수
비율에 맞게 훈련 세트와 테스트 세트로 나누어 준다.
from sklearn.model_selection import train_test_split
# train_test_split() 함수를 이용하여 훈련 세트와 테스트 세트 나누기, 매개변수 활용
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state = 42)
print(train_input.shape, test_input.shape)
print(train_target.shape, test_target.shape)
print(test_target)# stratify 매개변수를 활용하여 타겟 데이터에 0과 1을 적절히 배치
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify = fish_target, random_state = 42)
print(test_target)stratify 매개변수에 target data를 넣어서 도미와 빙어의 테스트 비율을 맞춰준다.
💡데이터 표준화
특성값을 일정한 기준으로 맞춰주기 위해 데이터 표준화를 진행. 표준점수를 이용한다.
# 표준화
train_scaled = (train_input - mean) / std
print(train_scaled[:5])이 코드를 이용해서 train_input의 모든 행에서 mean에 있는 두 평균값을 빼준다.
훈련 데이터의 평균, 표준편차를 이용해서 훈련 데이터를 표준화
샘플 데이터도 훈련 데이터의 평균, 표준편차 이용해서 표준화
'인공지능' 카테고리의 다른 글
| [혼공머신] 3-1 과대적합과 과소적합의 차이, 과소적합 해결 방법, 확인문제 (0) | 2025.01.13 |
|---|---|
| [혼공머신] 3-1 K-최근접 이웃 회귀, 회귀분석, 결정계수(R^2), 데이터 준비 (0) | 2025.01.13 |
| [혼공머신] 2-1 훈련 세트와 테스트 세트 (1) | 2025.01.02 |
| [혼공머신] 1-3 K-최근접 이웃 알고리즘 (0) | 2025.01.02 |
| ㄹㄹ (0) | 2024.10.04 |
'인공지능' Related Articles
more



